TLDR: Integrating an AI data assistant into your organization requires more than just technical know-how. We discuss the five must-have capabilities for a successful AI data assistant, backed by our hands-on tests with leading models like GPT-4, PALM-2, and Claude-2.1. We’re also excited to test Google’s newly released Gemini model and welcome suggestions for other models to evaluate. Let’s dive into what you need to consider for easy configuration, delightful user experiences, and manageable AI implementation in your data team.
We believe everyone will be bringing an AI data assistant into their organization. But before you decide to build it yourself, or go with a vendor it’s important to decide what criteria you have for an effective data assistant. It might be tempting to evaluate just its ability to write SQL in the dialect that you want. But there is a lot more to get right. This is why we get a lot of people talking to us after they tried to build it themselves 🙂
Before you go down the rabbit hole here are a couple of things to keep in mind. Whatever solution you choose, these two things have to be solved well.
- Configuring the assistant has to be easy for the people who maintain data. If the data maintainers are constantly needing to retrain or fine-tune your model, the end users will end up not trusting it and will never use it. And will just ask the maintainers the questions anyway.
- The end user experience has to be delightful. Response times need to be fast, and the format of the data returned needs to make sense. Their capabilities need to be discoverable and rich.
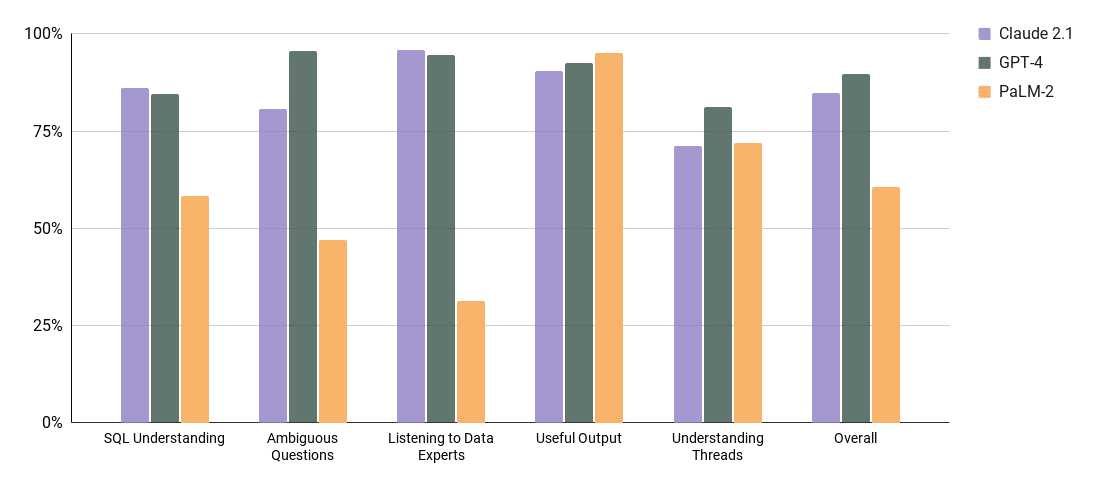
In order for an AI data assistant to satisfy both of those requirements we have a list of “must-have” capabilities to make sure the AI data assistant is successful in your organization. Here I will go through each “must-have” capability and run GPT-4, PALM-2, and Claude-2.1 through a series of tests we have to show how each model does.
Note: There are many models and we have tried a lot. I suggest using together.ai to see the full list of open-source models we tried as well. I’m just listing these three for now because they have a big enough context window, they can understand a chat context and are good enough at following instructions.
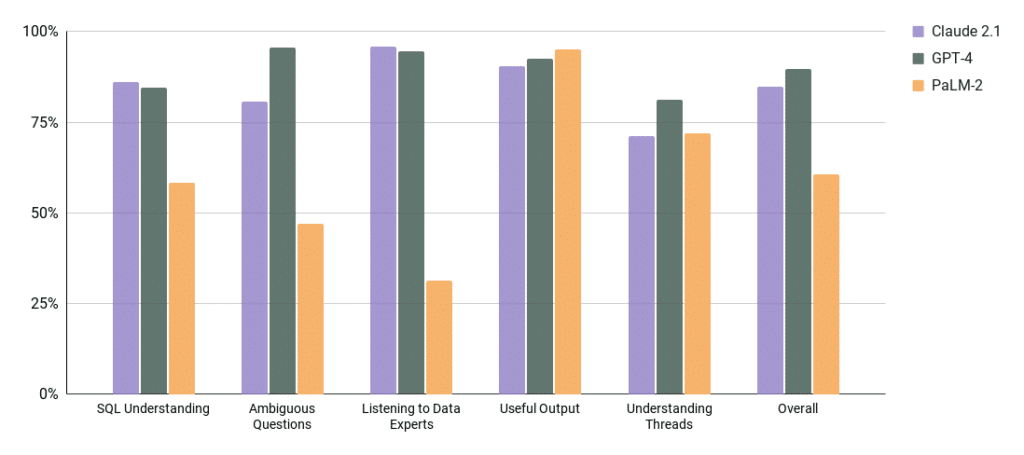
For each test in a capability we give a score from 0 to 1 on how each model did in that test. Then to calculate their percentage we take the sum of all scores of tests, divided by the number of tests per model.
Must-Have #1 Deep SQL Understanding
These are table stakes. We test our type conversion, date manipulations, join logic, CTE’s, Group by NULL LAST (a lot of them get this wrong)… There is a lot here and we borrow from Spider/SparC and Seq2SQL for inspiration on how to implement the tests. However, in a business context, we like to drill in a little further using our experience of how data tends to be laid out, and how people talk about data.
This is probably the easiest thing to get right for LLMs – here are our results:
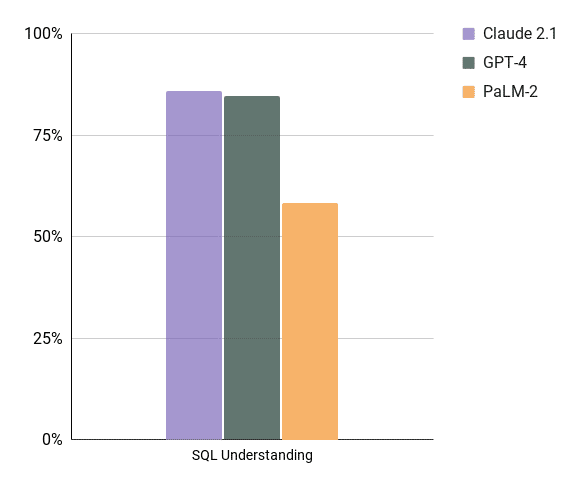
Note: PaLM-2 had trouble with holiday type questions in SQL, and some type conversions.
Must-Have #2 Handle Ambiguous Questions
One commonly overlooked observation is that most users lack the knowledge of how to pose a data-related question. This doesn’t mean the user is not smart. It means there is a big bridge between the context of what is in the user’s head vs the context of your data team. As a result the ai data assistant is here to help bridge that gap. This gap is not inferable from the data itself and as a result the Data Engineers/Analysts will always be valuable people. But in order for the AI to help bridge that gap the AI needs to be able to describe what it knows and what it doesn’t (more useful than you might expect). This category of tests is aimed at identifying how well each model can handle ambiguity so when questions like, “Which customer is best?”, “How well did my team do?” come up, the AI helps the user guide them to something useful for them.
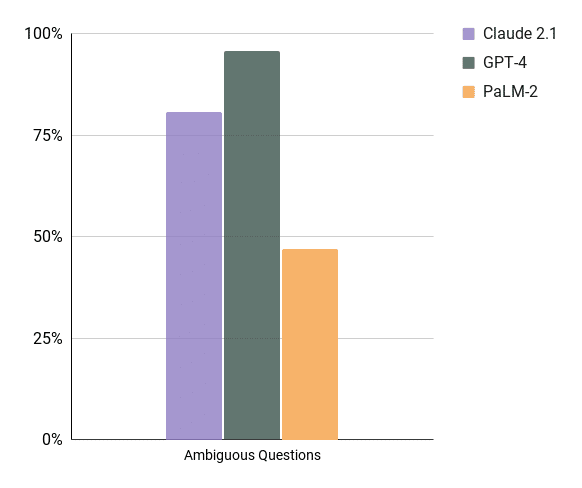
Notes: Claude 2.1 tended to be very wordy, and had some trouble with questions Like “Which Customer did well this year?” and had no idea how to help, PaLM-2 tended to hallucinate meanings more often than the other models.
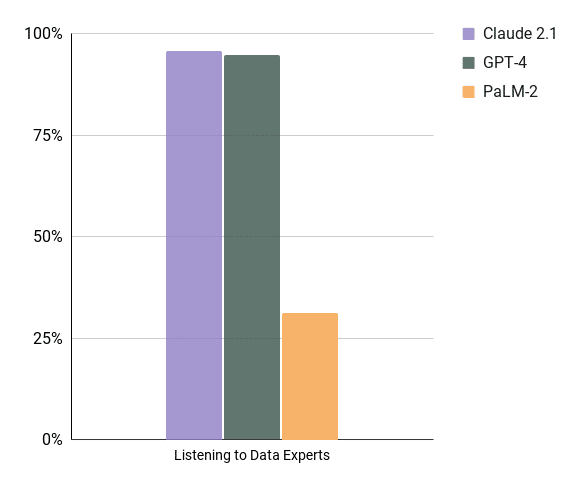
Must-Have #3 Listening to Data Experts
For a solution like this to work in any organization, the “Correct” way to do things will be seeded by the Data Experts. This is because they know when to do custom stuff that trickles into data models. This is the stuff that happens in the day to day life of maintaining data. For example, “ignore rows where customer = ‘test account’” “always convert the time column to New York Time Zone”, “Each query should use the date partition column”…. Going even further the AI assistant will need to be able to cite examples of queries blessed by the data team so that users can trust the information they receive.
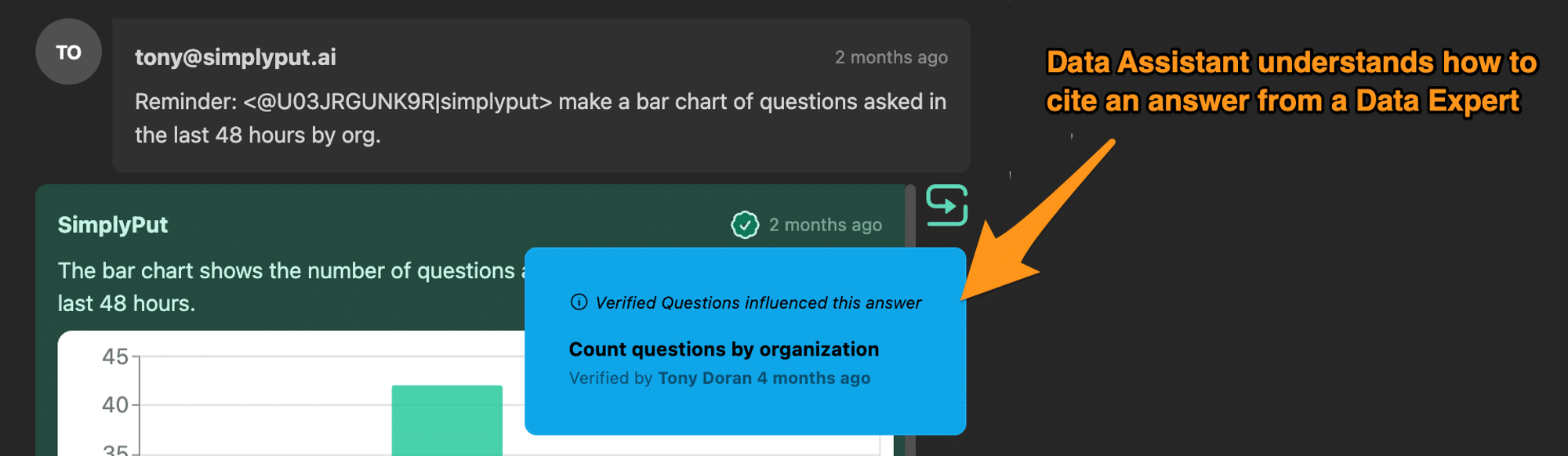
This is critical for AI and humans to work well together. Your end users shouldn’t be asked to trust a black box.
Must-Have #4 Useful Output
Let’s say the user asks a question that is answerable with data. But what should it display?
Sometimes it is better to display a sentence output with the data mixed in for example:
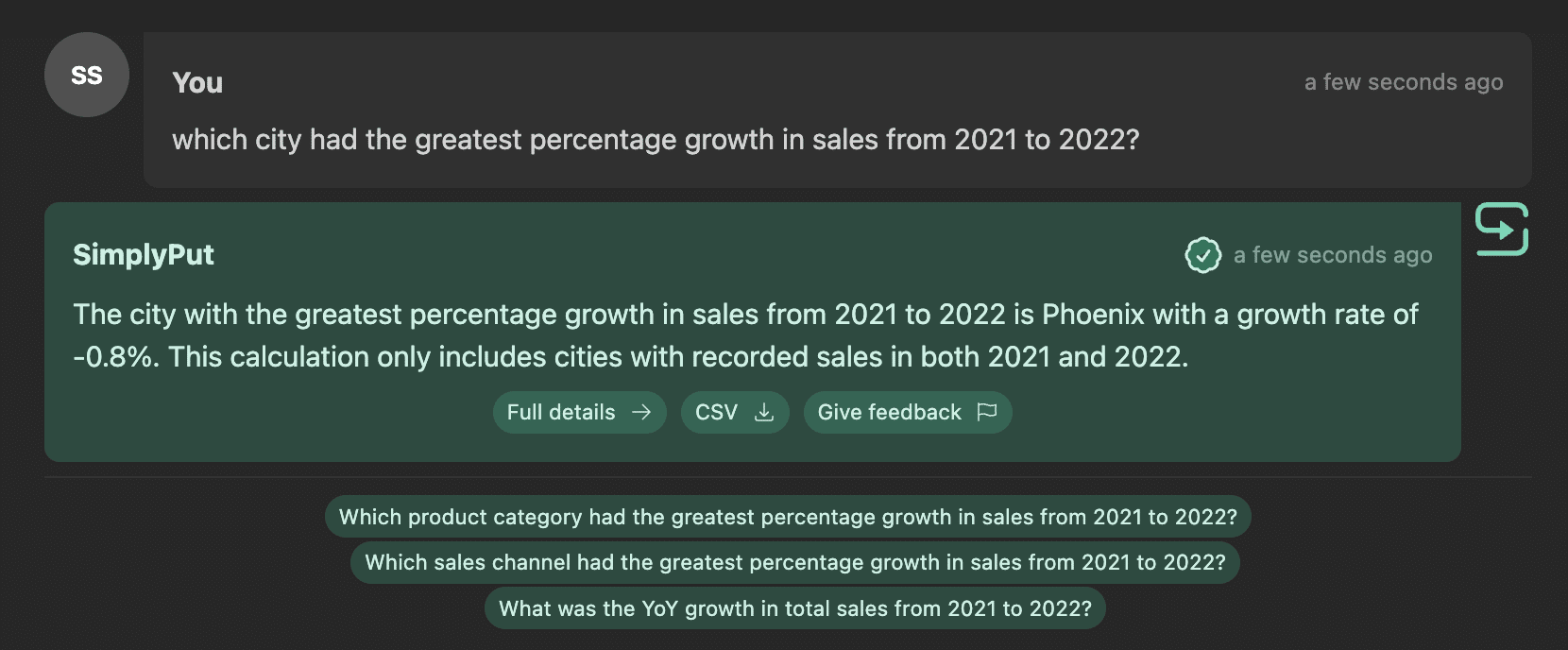
Other times you just want a list of results:
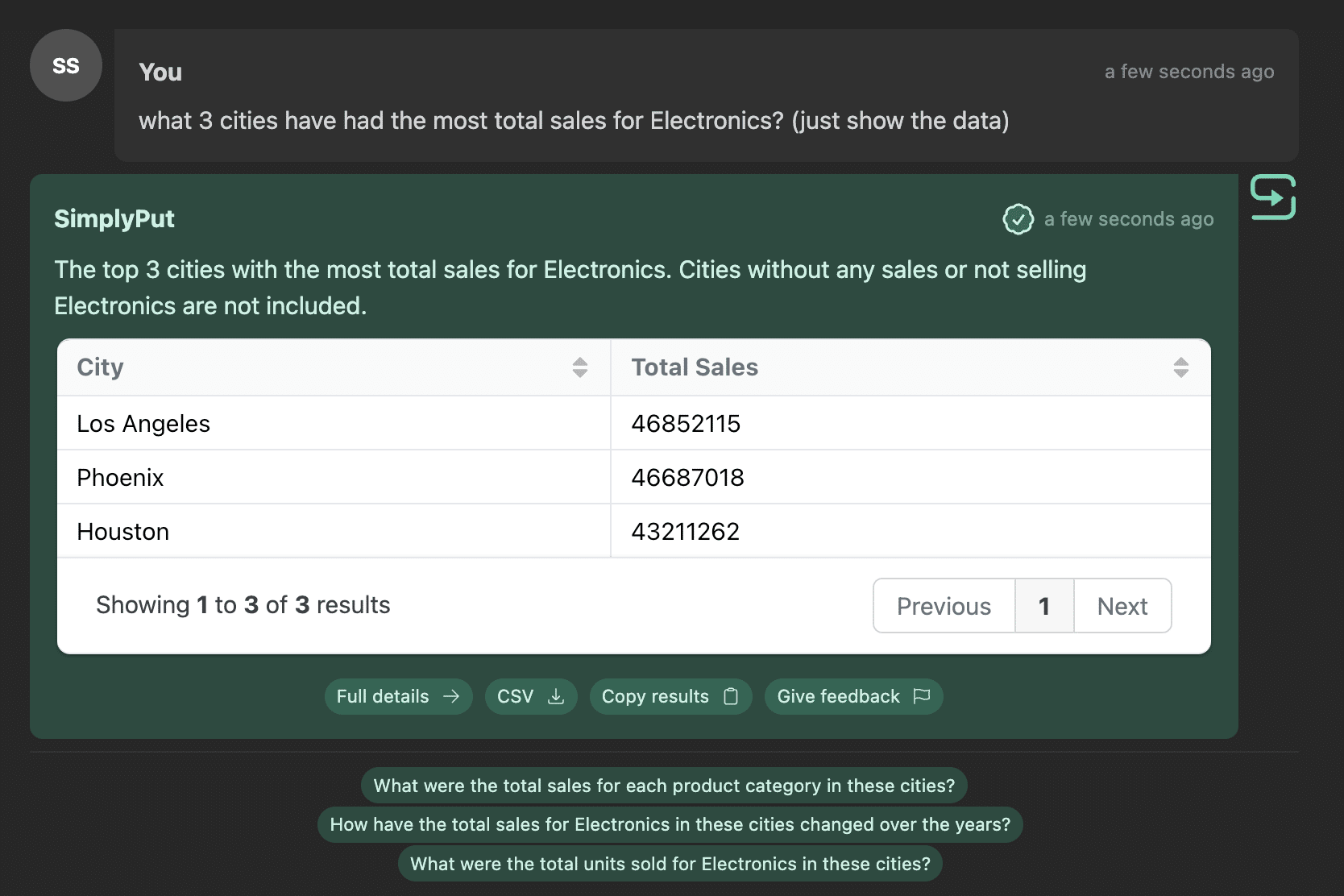
And other times you want a visualization:
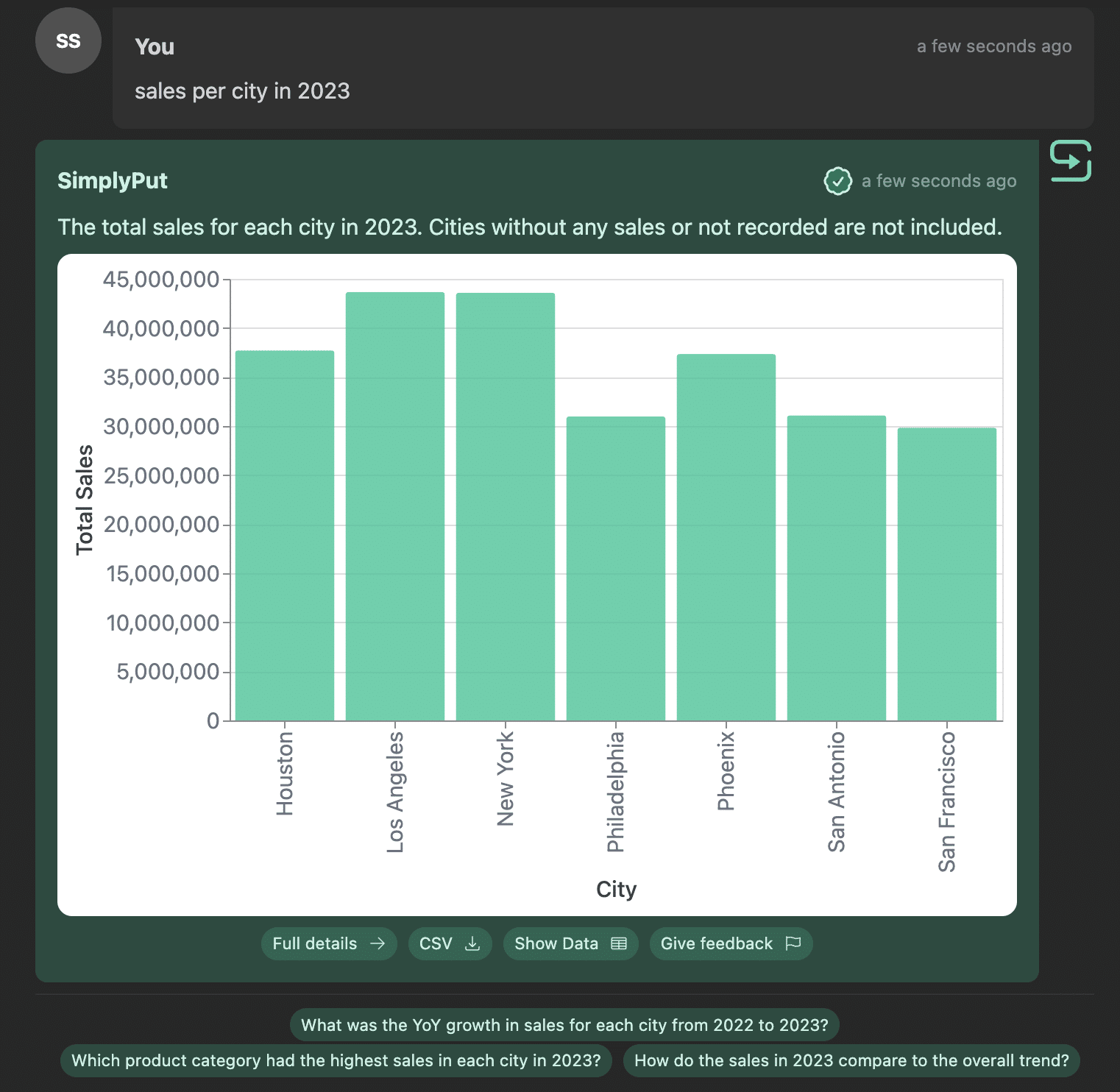
The AI needs to be able to understand when one output type is desired based on the current context. Here are testing results.
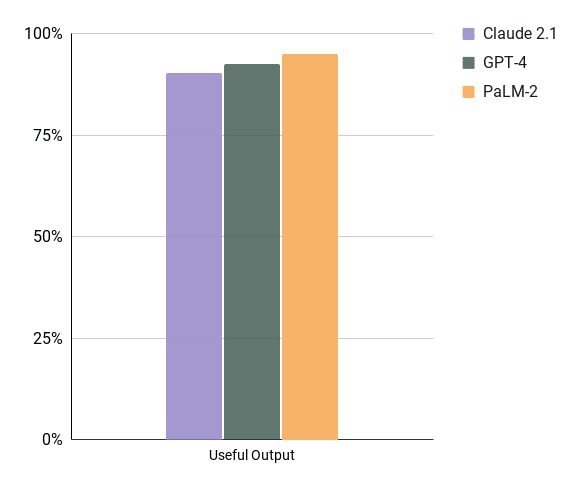
Note: The difference here could be adjusted based on prompting, but it’s safe to say all the models perform well at this task.
Must-Have #5 Understand Threads
Humans don’t interact with data in the “Question – Answer” paradigm. Having conversations with data is a much more human way of interacting with data. This is because sometimes the answer to your question triggers a refinement of your question, and you don’t want to have to restate the entire question in the reply. For example, look at this thread:
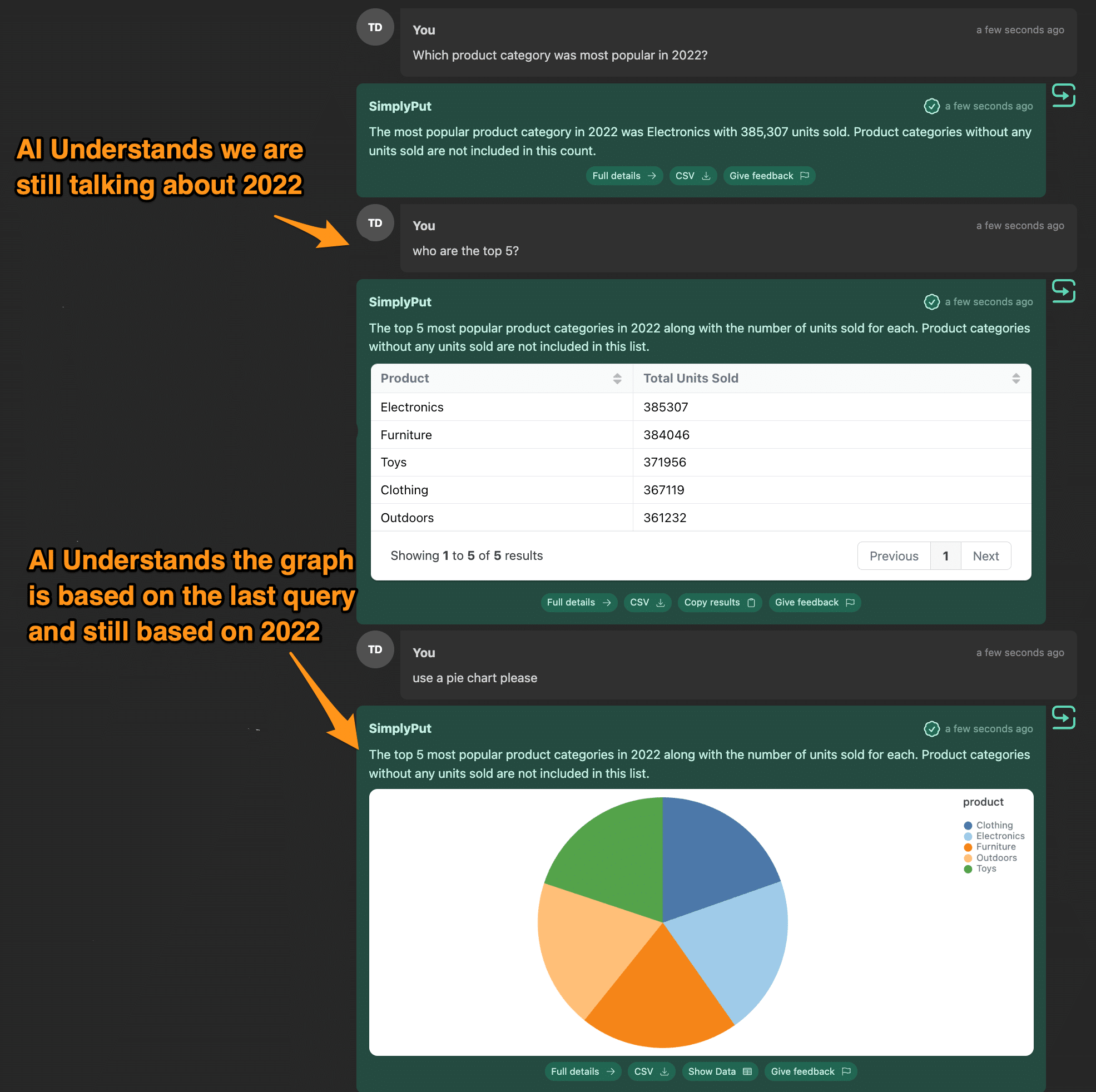
Notice that the AI needs to be able to understand what to do next based on the current thread. We tested threads with questions using “This”, asking the AI to change how the visualization looks, and switching aggregates with different lengths of the threads and with complicated questions.
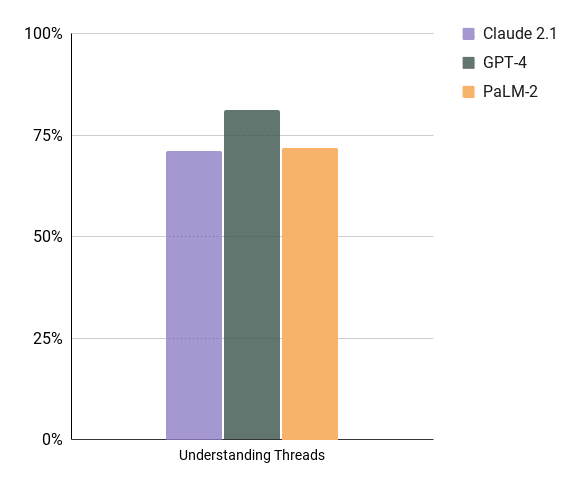
Note: All models suffered as soon as threads got over 20 questions long. GPT-4 hallucinated later than the other models did.
Conclusion
So putting this all together GPT-4 edges out as the best model.
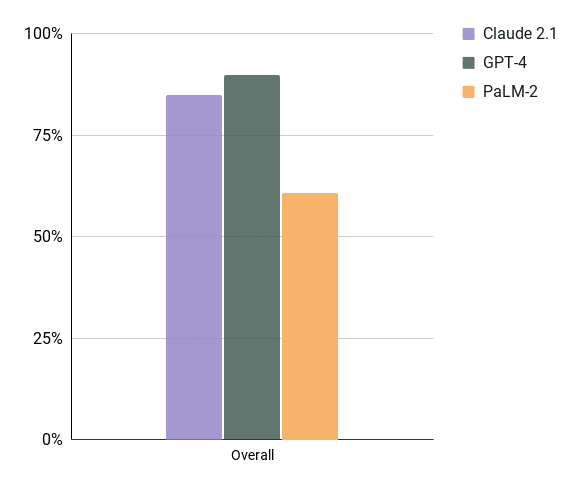
Note: That being said, that is what our results show as of right now. As models get better we run them through the tests and switch to the one that works the best. This works out for our customers. They can just focus on getting their data sorted and leave it for us to stay on top of this fast-paced world. But if you want to do this yourself I suggest finding the criteria that works for you and test the models thoroughly.
Extra note: We’re particularly excited about the recent release of Google’s Gemini model and look forward to testing soon, and if there’s a specific model you’d like us to evaluate, just let us know!
Tony loves the fascinating world of data. From the how to represent reality in bytes, to how to convey stories in data visualizations.